
Pythonのお勉強 No.3 HTMLデータの抽出、整形
はじめに
前回、Pythonで「HTMLデータの収集」をしました。

今回は、「スクレイピング」の後半、取得したHTMLデータについて「データの抽出、整形」を行ってみたいと思います。
Google ニュースから抽出したいデータは?
前回、「香川真司」と「久保建英」の最新ニュースを丸ごと取得してきましたが、その中から以下のデータを抽出したいと思います。
- ニュースのタイトル
- ニュースのリンク先URL(絶対パス)
- 抽出するニュースの件数は10件
Google ニュースのHTML構造を調べる
データ抽出にあたり、上記のデータがHTMLのどこに存在するのかを確認していきます。
ニュースのタイトルと見出しタグの関係を調べる
まずは、表面的な見た目から解析していきます。
Google ニュースを「香川真司 OR 久保建英」というキーワードで検索した結果について、 見出しタグ<h>の階層構造は以下のようになっています。

基本的に<h3>にニュースのタイトルが並んでいますが、一部<h4>にも並んでいることが分かります。
具体的なタグ、属性を調べる
次に、具体的にどのタグのどの値を抽出すべきかを解析していきます。

<h3>の階層について、ニュースがある場合は<div class="xrnccd ">タグが存在し、その配下の<article>タグで1件のニュースになっていることが分かります。<h>配下<a>タグのhref属性が「リンク先URL」、要素の内容が「タイトル」になっています。
<h4>の階層も似たような構造になっており、 ニュースがある場合は<div class="xrnccd ">タグ配下に<div class="SbNwzf">タグが存在し、その配下の<article>タグで1件のニュースになっています。<h>配下<a>タグのhref属性が「リンク先URL」、要素の内容が「タイトル」になっているのは<h3>の階層と同じです。
- <h3>階層のニュースが存在する場合、
<div class="xrnccd ">が存在し、その配下の<article>が1件のニュースになっている - <h4>階層のニュースが存在する場合、
<div class="xrnccd ">配下に<div class="SbNwzf">が存在し、その配下の<article>が1件のニュースになっている <article>配下<h>配下の<a>のhref属性が「リンク先URL」になっている<article>配下<h>配下の<a>の要素の内容が「タイトル」になっている
Pythonでスクレイピングしてみる
環境
- python 3.6.9
- requests 2.21.0
- urllib3 1.24.3
- bs4 0.0.1
- google-colab 1.0.0
ソースコード
# Pythonのお勉強 No.3 HTMLデータの抽出、整形
import requests
import urllib
from bs4 import BeautifulSoup
from google.colab import files
keyword = "香川真司 OR 久保建英"
url = 'https://news.google.com/search'
params = {'hl':'ja', 'gl':'JP', 'ceid':'JP:ja', 'q':keyword}
article_no = 1
# url、パラメータを設定してリクエストを送る
res = requests.get(url, params=params)
# レスポンスをBeautifulSoupで解析する
soup = BeautifulSoup(res.content, "html.parser")
# レスポンスからh3階層のニュースを抽出する(classにxrnccdを含むタグ)
h3_blocks = soup.select(".xrnccd")
for i, h3_entry in enumerate(h3_blocks):
# 記事を10件だけ処理する
if article_no == 11:
break
with open('result.txt', mode='a') as f:
# ニュースのタイトルを抽出する(h3タグ配下のaタグの内容)
h3_title = h3_entry.select_one("h3 a").text
# ニュースのリンクを抽出する(h3タグ配下のaタグのhref属性)
h3_link = h3_entry.select_one("h3 a")["href"]
# 抽出したURLを整形して絶対パスを作る
h3_link = urllib.parse.urljoin(url, h3_link)
# ニュースのタイトル、リンクをファイルに書き込む
f.write(h3_title)
f.write('\r\n')
f.write(h3_link)
f.write('\r\n')
article_no = article_no + 1
# h3階層のニュースからh4階層のニュースを抽出する
h4_block = h3_entry.select_one(".SbNwzf")
if h4_block != None:
# h4階層が存在するときのみニュースを抽出する
h4_articles = h4_block.select("article")
for j, h4_entry in enumerate(h4_articles):
h4_title = h4_entry.select_one("h4 a").text
h4_link = h4_entry.select_one("h4 a")["href"]
h4_link = urllib.parse.urljoin(url, h4_link)
f.write(h4_title)
f.write('\r\n')
f.write(h4_link)
f.write('\r\n')
article_no = article_no + 1
# ファイルをダウンロードする
files.download('result.txt')処理の流れは以下の通りです。
- 【構造解析】取得してきたGoogle ニュースのレスポンスを
BeautifulSoup()に渡し構造解析する - 【データ抽出】構造解析されたBeautifulSoupオブジェクトに対し、記事のタイトル/リンク先URLが記述されているタグの内容/タグの属性値を取得する
- 【データ整形】リンク先URLは相対パスで記述されているので、絶対パスに整形する
- 抽出/整形したタイトル/リンク先URLをファイルに出力する
実行結果
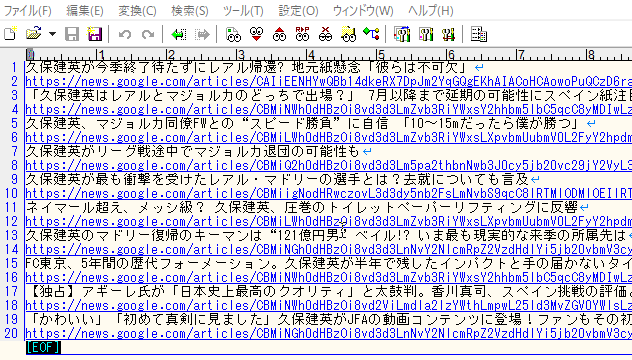
10件分のニュースのタイトル/リンク先URLがテキストファイルに吐き出されました。
リンク先URLは絶対パスになっており、そのままアクセスが可能です。
次回
次は、「WordPressの自動投稿」をしてみようと思います。

コメント