
Pythonのお勉強 No.2 HTMLデータの収集
はじめに
前回、Pythonの勉強を始めるにあたり実行環境の構築をしました。

今回は、Pythonで「スクレイピング」を、まずは「HTMLデータの収集」から行ってみたいと思います。
スクレイピングとは
Webスクレイピングとは、WebサイトからWebページのHTMLデータを収集して、特定のデータを抽出、整形し直すことである。
weblio辞典より
Webページ上の情報をPythonスクリプトを動かすことで取得します。
取得対象は、「Google ニュース」を「特定のキーワード」 で検索した結果にしたいと思います。
Google ニュースを取得するURLは?
「Google ニュース」を「特定にキーワード」で検索した結果を取得するためのURLを定めるため、実際にGoogle ニュースにアクセスしてURLを推測します。
まずは、「Google ニュース」のURL「https://news.google.com」にアクセスします。
「Google ニュース」のサイトが日本語で表示されます。
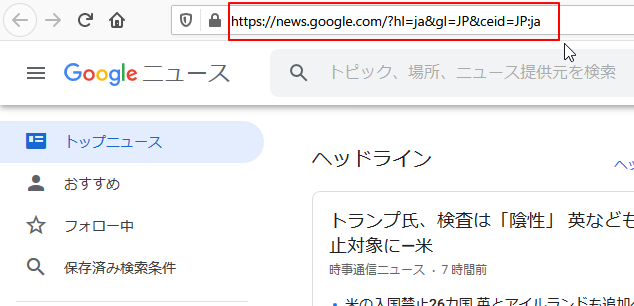
この時「アドレスバー」には、「https://news.google.com/?hl=ja&gl=JP&ceid=JP:ja」と表示されています。ここから、「hl=ja&gl=JP&ceid=JP:ja」という3つのパラメータが「日本」や「日本語」を意味していると推測できます。
さらに、「検索ボックス」に「香川真司」というキーワードを入力し検索します。
検索結果が日本語で表示されます。
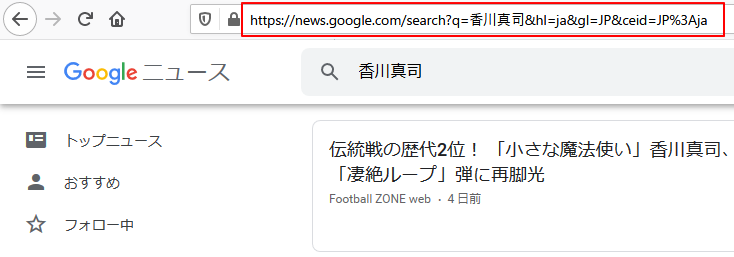
この時「アドレスバー」には、「https://news.google.com/search?q=香川真司&hl=ja&gl=JP&ceid=JP%3Aja」と表示されています。ここから、「/search」というパスと「q=香川真司」というパラメータで検索を実行していると推測できます。
- URL:https://news.google.com
- パス:/search
- 日本語を意味するパラメータ:hl=ja, gl=JP, ceid=JP:ja
- 検索ワード:q={キーワード}
Pythonでスクレイピングをしてみる
環境
- python 3.6.9
- requests 2.21.0
ソースコード
import requests
keyword = "香川真司 OR 久保建英"
url = 'https://news.google.com/search'
params = {'hl':'ja', 'gl':'JP', 'ceid':'JP:ja', 'q':keyword}
# url、パラメータを設定してリクエストを送る
res = requests.get(url, params=params)
# レスポンスを出力
print('----------')
print(res)
print('----------')
print(res.url)
print('----------')
print(res.text)requests.get()メソッドの引数に、URLとパラメータを指定するだけでレスポンスを受け取ることが出来ます。非常に簡単!!
以下、参考にさせていただきました。

実行結果
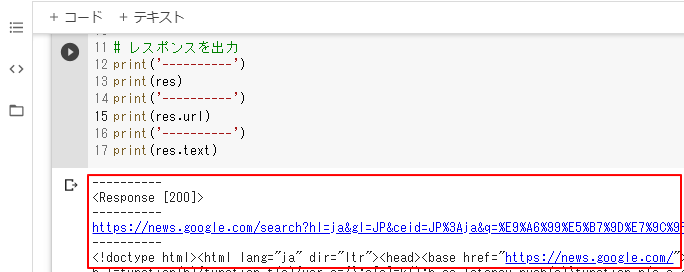
無事、HTTPレスポンスコード:200(OK)で、HTMLが返ってきました。
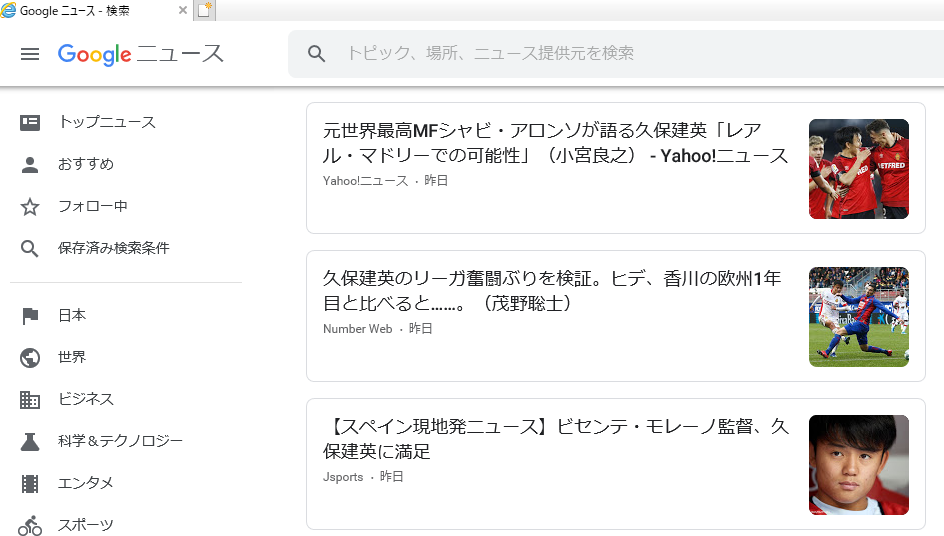
6行目のレスポンス内容をファイルに保存しブラウザで表示させると、ちゃんと「Google ニュース」の結果が取得できていることが確認できました。
次回
次は、「スクレイピング」の後半「HTMLデータの抽出、整形」をしてみようと思います。

コメント